Results
- Shortening how long it took to access data—from days to instantaneous, via the Data Pipeline
- Broadening possibilities of data projects (more time to do intricate work!)
As a digital-only, startup media company, Mashable has always relied on data to help inform its editorial choices. The latest step in its evolution brings this strategy even more into focus as the organization has brought together previously separate teams, audience development, video, social and more, into one content team. Their mission is to focus on the best way to tell stories.
“We need to think about the audience at every step. The day of publishing stories and handing it off to the social team to promote are over. In my mind, they’ve been over for a long time.”
Gregory Gittrich, Chief Content Officer, Mashable
At the heart of this storytelling effort? Using data science to inform their decisions. But Chief Data Scientist, Haile Owusu, found out getting access to the company’s own data was half the battle, until Parse.ly provided Mashable with a better solution.
“Parse.ly provided us with the actual ability to pursue analyses beyond dashboard aggregations.”
Haile Owusu, Chief Data Scientist, Mashable
The Challenge: Access the data
Mashable had used another third-party data provider to store view log data. To access that data, however, the team had to call the data provider and have them manually set up a FTP server. The process also required them to buffer and monitor the server so that the files wouldn’t overwhelm the limited storage provided.
The result? It would often take multiple days to pull simple information. And if the team forgot to request a field? The process started all over again. Owusu and his team found this extremely frustrating: “It was OUR data.”
The Solution: Parse.ly’s Data Pipeline
In 2016, Mashable integrated Parse.ly’s raw data pipeline with the goal of obtaining more granular information about its data. Upon integration, the team received its own secure S3 Bucket and Kinesis Stream, hosted in Amazon Web Services. This provided them with full access to all of their historical raw data (batch/bulk) and to new analytics data as it arrives (real-time/streaming).
The Mashable team was able to push this data to BigQuery, its data warehouse, and scale its infrastructure to help uncover specific and actionable information to benefit its editorial team. Said Chief Data Scientist Haile Owusu: “Parse.ly provided us with the actual ability to pursue analyses beyond dashboard aggregations.”
About Parse.ly’s Data pipeline
Parse.ly’s Data Pipeline unlocks all the data behind Parse.ly’s analytics, and analyzes it for an organization’s own needs. It is specifically optimized to make it trivial to bulk load Parse.ly’s data into existing data warehouse tools — allowing organizations like Mashable to fully own their analytics data and ask any question they want of it. This provides data analysts with an endless supply of good, clean raw data about their company’s website interactions.
Content Analytics: Taking content into account
With Parse.ly’s Data Pipeline bringing content data to Mashable’s team, they were able to build a user-item similarity matrix quickly. Without needing an elaborate architecture of third-party software, the data science team quickly found patterns in their audience that helped answer questions the editorial and business teams had asked of them.
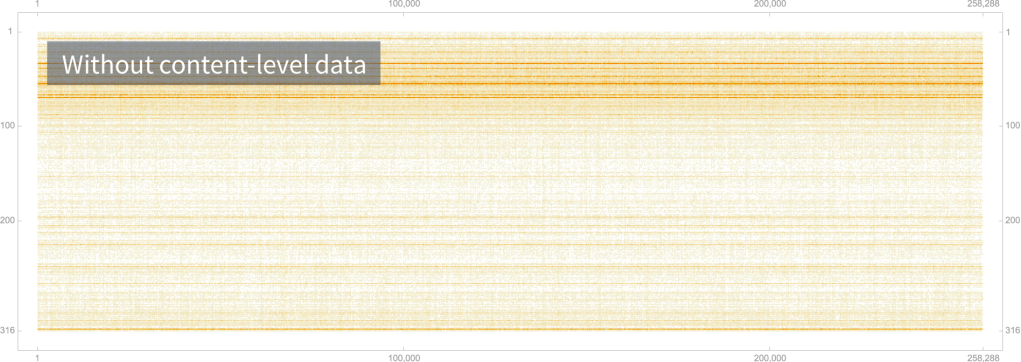
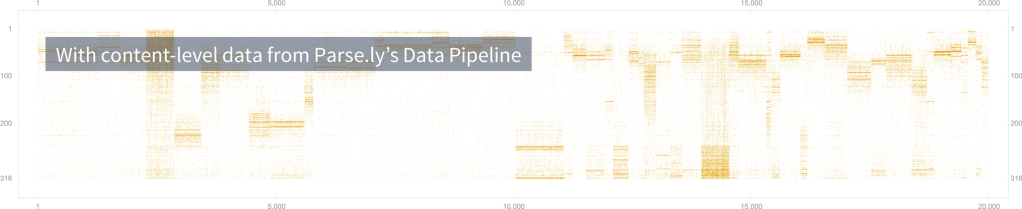
Enriched Data: Combining data sets FTW
Using the Data Pipeline also means that Mashable can use content data in combination with custom events and other data sets, such as demographic data. Collecting and processing is as fluid as a simple query — no “faffing about” for days just to complete a join.
Using data from Parse.ly’s Data Pipeline has made audience profiles and article recommendations more tractable and adjustable in ways that were not possible with its previous data provider. And further, according to Owusu, building recommendation systems and identifying viewer clusters was impossible before.
“Of course there are a slew of third-party vendors happy to offer an out-of-the-box recommender, but building one out forces an acquaintance with one’s own viewers that one simply doesn’t get without access to granular data,” said Owusu.
Thinking Ahead: Improving data strategy at Mashable
Prior to Parse.ly’s Data Pipeline, Mashable didn’t even broach certain analyses because the time cost of retrieving data was prohibitive. Now, the organization has a whole range of accessible approaches to strategic questions most recently related to general business intelligence and personalization of its site experience.
For publishers building data science teams, this type of data is the only way to get to the heart of the questions endemic to modern publishing: Who is our audience? What do they enjoy? Under what circumstances do they return to further enjoy our offerings?
Do more with your data
Find out more about using the Data Pipeline today.